Strategies to Handle Dynamic Web Elements in Selenium

Identifying the right web elements to perform the required operations are the first step in automating any test cases. This step gone wrong, the entire test fails. So using efficient strategies for web element identification is very critical. WebElemnet not found is the most common error you could get once you start running scripts initially. Identifying the web elements using different locators such as IDs, Name, XPath or CSS from the HTML snippets of web page looks pretty straight forward. Right? Then what has gone wrong? But it isn’t that straight forward always.
Sometimes IDs and classes of the web element keep changing. Such web elements are called Dynamic web elements.These are database based elements and its values get refreshed everytime the database gets updated.For example, let’s take the below example of a button on the rediff sign up page. It can be seen that the ID and class of the web element keep changing every time the page is loaded. So we cannot use this ID for web elements identification.
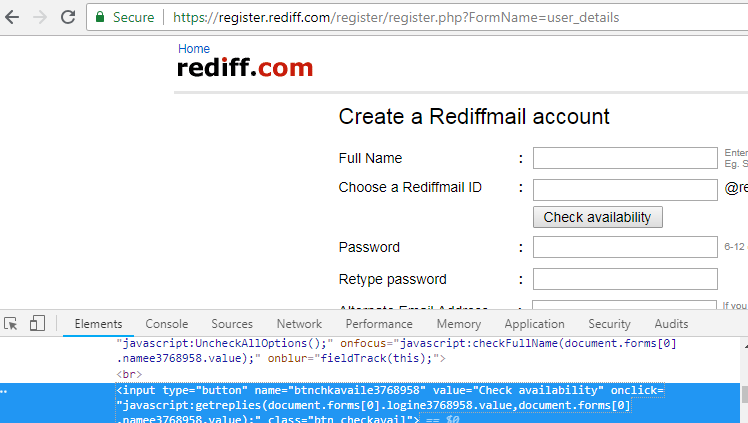
<input type="button" id="btnchkavaile3768958" value="Check availability" class="btn_checkavaile3768958">
The number '3768958' keeps changing everytime.
In this case we need to use some other methods to identify the web element. Here are some methods that you can use to identify such dynamic web elements in your web page.
1.Absolute Path method
This is the easiest way to solve the issue. Absolute XPath is the path starting from the root. It will be something like :
/html[1]/body[1]/nav[1]/div[1]/form[1]/div[1]/div[1]/div[1]/artdeco-typeahead-deprecated[1]/artdeco-typeahead-deprecated-input[1]/input[1]
But the risk with this method is, if something changes in the structure of your web page, your code will break. So this is not a recommended method.
2.Use Relative XPath using contains or starts with text
This is the preferred method for handling dynamic web elements if you observe a pattern in the attribute values like ID or Class of the web element.
For eg consider the HTML snippet:
<input type="submit" id=" submit_334350" value="Subscribe">
This Subscribe button on the page has an ID with a dynamically changing number in it (‘334350’). This keeps on changing every time you refresh the page. But it always starts with submit. So you can use a relative XPath as given below to identify the web element:
XPath - //input[starts-with(@id, ‘submit_’)]
Now, consider another example:
<input type="submit" id=" 1002-subscribe" value="Subscribe">
In this case you can write XPath as:
XPath - //input[contains(@id, ‘subscribe’)]
3.Identify by index
Sometimes, you will have multiple elements with same locator value. For example there may be two submit buttons with id starting with ‘Submit’. In this case you can use findElements method and locate the element using the index.
driver.findElements(By.xpath(//*[contains(@id, ‘submit’).get(0).click();
Here get(0) is used to get the first web element with matching XPath.
4.Use Multiple attributes to locate an element
To identify a particular element you can use multiple attributes if a single attribute is not enough to identify your web element uniquely.
Xpath- //button[starts-with(@id, 'save') and contains(@class,'publish')]
These are just a few ways for coping up with dynamic web elements. You will have to use different strategies depending on your situation. The ultimate aim should be to identify a web element uniquely and whatever is your locator strategy, you should always be able to locate the element irrespective of change in attribute values dynamically.
How much is a great User Experience worth to you?
Browsee helps you understand your user's behaviour on your site. It's the next best thing to talking to them.

