Locators Used In Selenium For Object Identification
While writing scripts for testing a web application using any automation tools, the tool should identify the web elements or web objects appropriately to perform the desired operation like click or enter text on the corresponding web element/object. This is called object identification. Every application is made of various objects like links, button, text box, drop down selector, radio button, list boxes, sliders, etc.
Accurate object identification is a very critical part of automating your application as only if you identify the right object, rest of your script runs without throwing errors. Tools like QTP and RFT which have record and playback features have mechanisms to store the properties of the GUI objects while recording and recognize and identify these objects later during run time. These tools also have features like ‘Object spy’ which helps you capture properties of objects you want to use in your tests.
In Selenium, however, object identification is the responsibility of the automation tester writing scripts. Selenium uses a concept of ‘Locators’ for identifying objects. The findElement method in Selenium can be used to identify the elements. It takes a locator or a query object ‘By’ object and returns an object of type WebElement. ‘By’ object can be used with the various locator strategies available. There are 8 locators used in Selenium to identify the elements on a webpage.
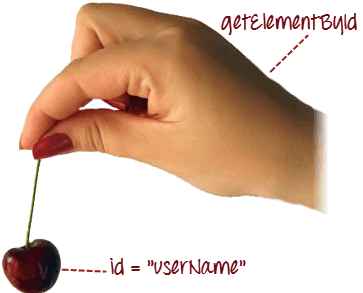
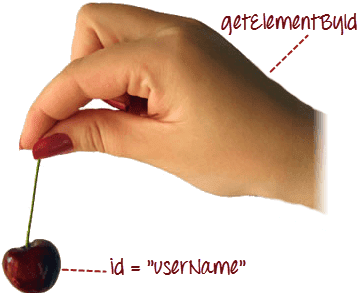
ID
The most efficient and preferred way to locate web elements on a web page is by ID as ID will be unique for every element. Thus, IDs being the safest and fastest option to identify an element is the first choice for object identification.
Syntax: driver.findElement(By.id(“Element ID”))
But, many cases IDs may not be mentioned in HTML codes of the webpage. In such cases you would have to go for other locators.
Name
The second preferred choice if ID is not mentioned for the element. But ensure the Name attribute is unique in the webpage because like IDs, Name attribute need not be unique always. So there is a chance that there may be other elements having same Name and your script might end up selecting the wrong element.
Syntax: driver.findElement(By.name(“Element Name”))
Class Name
This is yet another locator used for identifying web elements. But if you are using Class name for element identification, make sure it is unique. There may be many elements with same class name. This locator is often used in identifying a group of elements having same class and performing some operations on it.
Syntax: driver.findElement(By.className(“Element className”)).
TagName
Here Selenium finds the elements using tag name. Tag names are a good choice for group elements like Select/Check boxes, drop down menu, etc.
Syntax: driver.findElement(By.tagName(“Element TagName”))
LinkText
The link text is the visible clickable text in a hyperlink. It is the text in between the anchor tags. Here also, make sure of uniqueness. There may be multiple links with same text such as in repeated header and footer menus. If there are repeated occurrences, Selenium will perform the action on the first matching element with the link text.
Syntax: driver.findElement(By.linkText(“Link Text”))
Partial LinkText
You can use partial LinkTexts also same way as you use LinkTexts. This is very helpful in cases where you know part of the link text would never change in the application. So that even if remaining part of link text changes your code doesn’t break.
Syntax: driver.findElement(By.PartialLinkText(“PartialLink Text”))
XPath
XPath is the used for navigation through XML documents. Since an HTML document is also an XML document (xHTML), every element in a web page can be identified using XPath. There are two types of XPath- Absolute or Native XPath and Relative XPath. Absolute XPath uses the complete path starting from the root element to the desired element while relative XPath starts from anywhere in the HTML DOM structure. Relative XPaths are usually preferred because if you use absolute XPath for identifying elements, and later if the structure changes the path will break.
The greatest advantage of using XPath for element identification is that it provides many different ways to locate same element. The syntax for XPath expression is:
XPath = //Tagname[@attribute=’value’]
where Tagname can be tag names like input, Div, img, etc, attribute can be any attribute like id, name, etc and value is the value for the attribute.
So you can use different attributes and different strategies to identify an elemnt using XPath.
To identify an element using XPath, the syntax in Selenium is:
Syntax: driver.findElement(By.xpath(“Element XPath expression”))
CSS
CSS is used for providing styles to your webpage. These can be used for identifying elements in the web page. This is considered to be a fastest option for identifying elements. CSS expression also has a syntax similar to XPath:
CSS expression= Tagname[attribute=value]
To identify an element using CSS, the syntax in Selenium is:
Syntax: driver.findElement(By.cssselector(“Element css expression”))
Now, we have seen the different locators used in selenium for web element identification and how you can use the findElement() method for these locators. Now, how do you get the values for these locators? Don’t worry. It’s quite easy these days with most of the browsers having built in browser inspectors to view HTML snippets. Look out for our next article for the steps to get the locators using browser Inspector.
How much is a great User Experience worth to you?
Browsee helps you understand your user's behaviour on your site. It's the next best thing to talking to them.

